
หนึ่งในการประยุกต์ใช้งานเทคโนโลยีปัญญาประดิษฐ์ (AI) นั้นคือการสร้างระบบอัตโนมัติ (Automation) เพื่อทำงานแทนมนุษย์ในกรณีที่ข้อมูลมีจำนวนมหาศาล การใช้ AI ในงานวิจัยด้านห้องสมุดดิจิทัลนั้นได้รับความสนใจเป็นอย่างสูง โดยวัตถุประสงค์หลักเพื่ออำนวยความสะดวกต่อผู้ใช้งานในการสามารถสืบค้นข้อมูลที่ต้องการจากคลังข้อมูลได้อย่างแม่นยำ สะดวก และมีประสิทธิภาพ
อัลกอริทึม (Algorithm) คือ ขั้นตอนวิธีในการแก้ปัญหาเชิงคำนวณ งานวิจัยที่เกี่ยวข้องกับศาสตร์ด้านคอมพิวเตอร์ ล้วนแต่เป็นการคิดค้น วัดผล และประยุกต์ใช้งานอัลกอริทึม ซึ่งอัลกอริทึมเหล่านี้ ได้ถูกนำเสนอในเอกสารทางวิชาการ (Scholarly Documents) และได้ถูกตีพิมพ์ในวารสารวิชาการต่างๆ
การคิดค้นและตีพิมพ์อัลกอริทึมใหม่ๆ นั้น นักวิจัยจำเป็นต้องใช้งานอัลกอริทึมก่อนๆ ในหลายรูปแบบ ไม่ว่าจะเป็นการนำมาพัฒนาต่อยอด (Extension) การใช้งานโดยตรง (Direct Usage) หรือเพียงแค่ศึกษาข้อมูลเพื่อทำการอ้างอิง (Mention) ถ้าหากสามารถสร้างกราฟความรู้ที่แสดงการใช้งานอัลกอริทึมจากเอกสารทางวิชาการทั้งหมดได้ ก็จะมีประโยชน์มหาศาลในงานวิจัยด้านห้องสมุดดิจิทัล ซึ่งจะสามารถใช้สร้างดัชนีตัวชี้วัดด้านอิทธิพล (Influence) และความสามารถในการประยุกต์ใช้งาน (Generalizability) ให้แต่ละอัลกอริทึมได้ ทั้งนี้ยังสามารถใช้กราฟความรู้ดังกล่าวในการศึกษาวิวัฒนาการของอัลกอริทึมตั้งแต่อดีตถึงปัจจุบัน ได้อีกด้วย
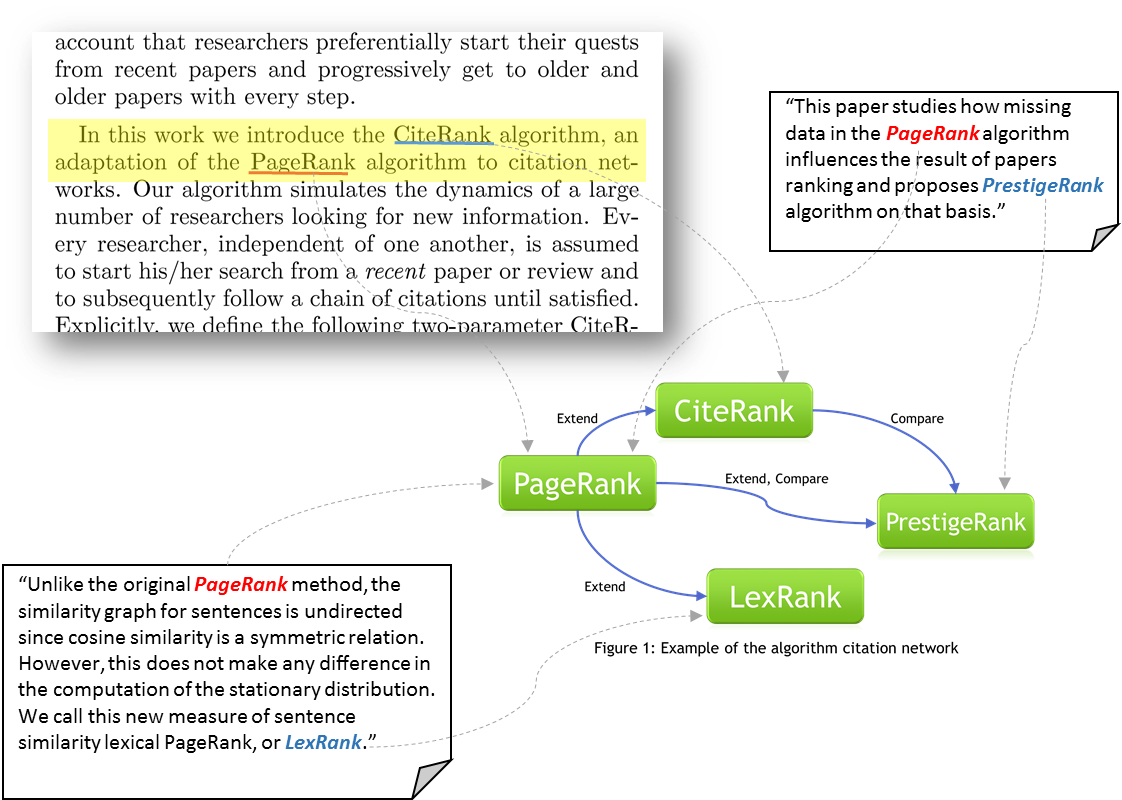
งานวิจัยนี้ นำโดย รองศาสตราจารย์ ดร. ศุภวงศ์ ทั่วรอบ หัวหน้ากลุ่มวิจัย Machine Intelligence and Knowledge Engineering และ Professor Dr. Peter Haddawy รองคณบดีฝ่ายพัฒนางานวิจัย เป็นการนำเสนอเทคโนโลยี AI มาเพื่อระบุประเภทของการใช้งานอัลกอริทึมอย่างอัตโนมัติจากบริบทอ้างอิง (Citation Context) โดยแบ่งประเภทของการใช้งานอัลกอริทึมออกเป็น 3 ประเภทคือ การต่อยอด (Extension) การใช้งาน (Direct Usage) และการอ้างอิง (Mention) และใช้กระบวนการเรียนรู้ด้วยเครื่องแบบ Ensemble ในการรวมการตัดสินใจของโมเดลย่อยที่เรียนรู้คุณลักษณะ 2 ด้านจากตัวข้อมูล นั่นก็คือ เนื้อหา (Content) และบริบท (Context) และใช้ประบวนการ Weight Average ในการเฉลี่ยแบบถ่วงน้ำหนักค่าความน่าจะเป็นที่ได้ออกมาจากทั้ง 2 โมเดล จากการทดลองพบว่าวิธีที่นำเสนอนี้สามารถได้ค่า F1 สูงถึง 74.9% สำหรับการระบุแบบละเอียด และ 90.5% สำหรับการระบุแบบหยาบ
งานวิจัยนี้ได้รับการตีพิมพ์ในวารสารวิชาการนานาชาติ IEEE Transactions on Knowledge and Data Engineering ในปี 2020 ซึ่งเป็นวารสารชั้นนำระดับ Q1 และอยู่ในอันดับ Top 5% ด้าน Information Systems โดยผู้ที่สนใจสามารถอ่านผลงานวิจัยฉบับเต็มได้ที่ https://ieeexplore.ieee.org/document/8700263
รู้หรือไม่: งานวิจัยนี้ได้ถูกนำไปพัฒนาต่อยอดเป็นแอพพลิเคชั่นชื่อ AlgoExplorer โดยนายชนาธิป พรประสิทธิ์ และนายธนดล บุญเกิด นักศึกษามหาวิทยาลัยมหิดล โดยมี รศ.ดร.ศุภวงศ์ ทั่วรอบ เป็นอาจารย์ที่ปรึกษา ซึ่งได้รับรางวัลชนะเลิศอันดับ 3 หมวดโปรแกรมวิทยาการข้อมูลและปัญญาประดิษฐ์ (Data Science and Artificial Intelligence Application) จากงานมหกรรมประกวดเทคโนโลยีสารสนเทศแห่งประเทศไทย ครั้งที่ 18 ระหว่างวันที่ 13-15 มีนาคม 2562

รูปเพิ่มเติม:
